FX Euro-Dollar Dominance Strategy
Galileo Galilei was deemed heretical but was later vindicated when the world caught up to his brilliance. This post might make me a quant-heretic without the brilliance part.
Setup
I was reading this book; Trading Fixed Income and FX in Emerging Markets, and the authors mentioned multiple times about how USD and EUR are significant drivers of returns in the FX space. Well, that was enough for my brain to start wandering around. I wanted to try to create a trading strategy based on these observations.
Note: This is the first instance where I tried to create a strategy from scratch (there’s no such thing as an original idea, but I can’t find any papers/resources on this). I hope the Quant Police Force would be willing to kindly educate and correct me where its needed.
My (slightly crazy) idea
My hypothesis is:
- USD and EUR are significant drivers of returns in the FX space
- USD and EUR take turns being the more significant driver of returns
- When a currency is the more dominant driver vs the other, it’s bullish for the currency and bearish for the other one
Quantifying Dominance
I thought a lot about how to quantify “dominance” in this setting. My first idea was to use the returns of EURUSD as a proxy of dominance, but that doesn’t seem right. If I did that it would just be a strategy based on EURUSD momentum.
Second idea was why not we regress every single currency against DXY and ICEEX and then maybe take the total r-squared? Say if total R-squared for DXY is higher than ICEEX → USD is more dominant than EUR. But I was not really comfortable with using these indexes as the default baskets, since the weightings of these indexes feel arbitrary. It just doesn’t feel “intentional” enough.
It is an indisputable fact of the universe that the best ideas come to you when you’re in the shower, and yes that was what happened. In the shower I was thinking that what I should do is:
Step 1: Create two dataframes, first is XXXUSD, second is XXXEUR for all the currencies in my universe
Step 2: Run PCA on each dataframe
Step 3: Calculate the proportion of variance explained by the first K principal components for both dataframes (these will be our proxies for dominance of USD and EUR, and they are directly comparable!)
If this idea is stupid please leave a comment since it sounded groundbreaking in my own head; and for good 5 seconds I thought I was gonna be the next Fischer Black.
I would like to point the readers to @GautierMarti1’s gitlab, it has multiple posts on PCA which are very much worth reading.
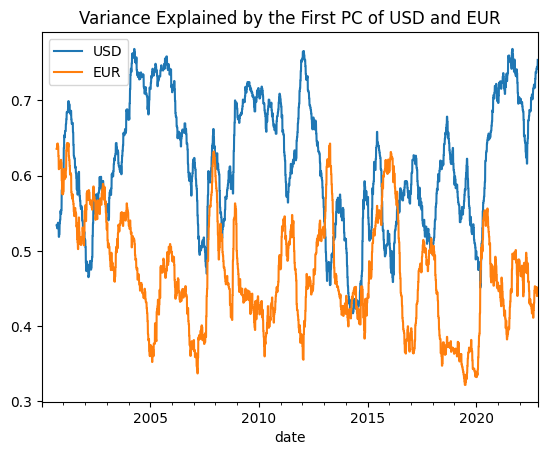
In the above plot we can see that on average USD explains much more variance in the FX space compared to EUR, with some brief periods where EUR is higher than USD. Now I will take the difference of the two series as a proxy to get what I call USDvEUR Dominance Spread (if this thing is somehow legit and it catches on someday I should include my own name at the beginning).
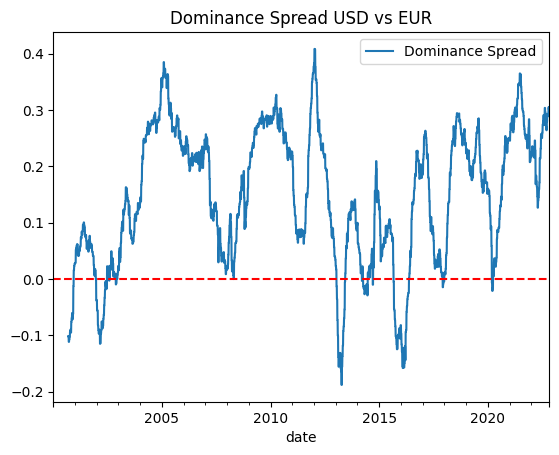
If spread compresses → EUR dominance increases, if spread widens → US dominance increases.
So our trading rule is if USD dominance increases → long USD short EUR, and vice versa.
Performance
As usual our training set is 2000-2015, test set 2016-2022. Let’s look at the training set performance.
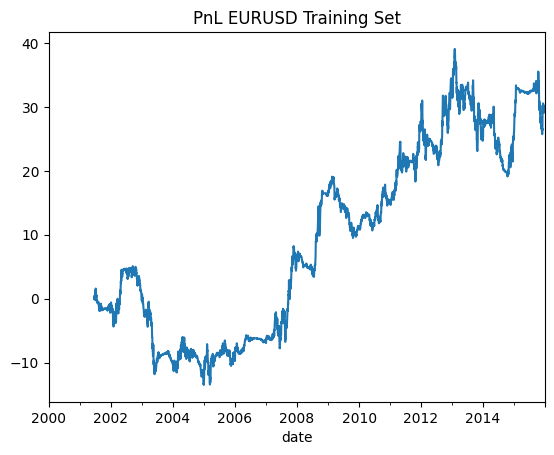
Sharpe: 0.274
The performance is nothing to be bragged about. Seems like pre-2005 the strategy was not working at all. And it has a huge drawdown in 2012-2014 as well.
At this point I’m quite bothered by the fact that I’m only trading 1 instrument; EURUSD. How am I going to sleep at night feeling like a Quant™ if I only trade 1 instrument? What am I, a discretionary macro trader?
All jokes aside, I still want to trade multiple instruments for diversification effects that we all love. Since I’m trading EUR, the low hanging fruit is to include all the other currencies in Europe. So let’s do that.
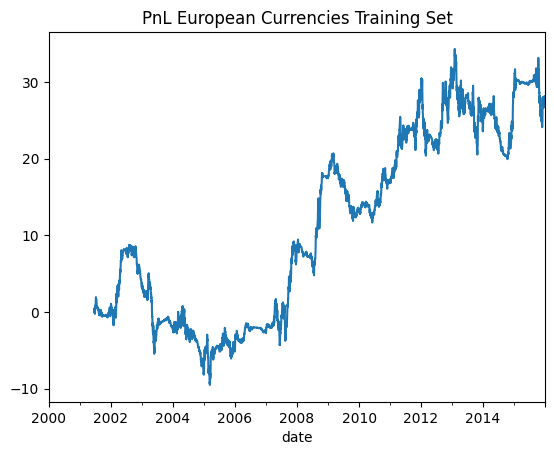
Sharpe: 0.289
Not much improvement tbh. And I just 7x-ed my trading without getting a significant improvement, so I’m just gonna go back to EURUSD only.
At this point I ran out of ideas to make justifiable changes to the strategy. So I’m gonna leave the strategy as it is. I don’t really have high hopes, but I’ll include the out-of-sample performance for completeness.
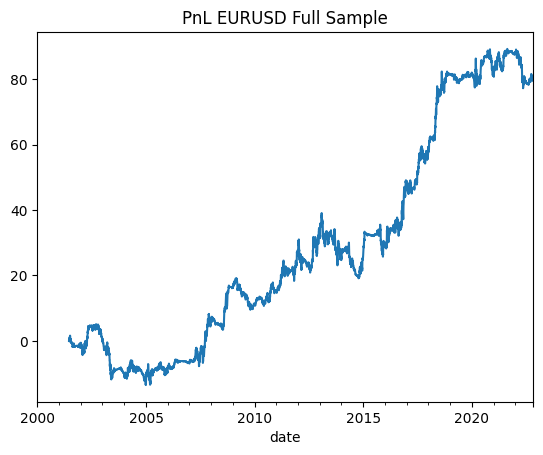
Sharpe (Full Sample): 0.478
Sharpe (OOS): 0.844
Well that was quite unexpected. I wouldn’t rule this strategy as a success yet, she will go straight into the “there might be alpha here but I need to monitor it for some time first” bucket. Or maybe I should see how this strategy interacts with my overall portfolio instead of looking at its standalone performance. Maybe introduce it as a tilt on my EURUSD exposure? (ideas stolen from @macrocephalopod and )
@be20684347 @therobotjames @jose34730 The original sin is thinking that you could/should trade this as a standalone strategy (a la “night shares”). If it’s a real effect then it makes sense to tilt a mid-frequency strategy to be a bit longer overnight and a bit flatter in the day.
— cephalopod_v7 (wirefraud (parody)) (@macrocephalopod) 9:59 AM ∙ Nov 26, 2022
The rest that I share are small edges here and there that likely needs to be layered or introduced as portfolio tilt, or used as part of diversified risk premia - factor exposure does not constitute as the best form of pure alpha, and are often arbitraged away once made known.
— HangukQuant (@HangukQuant) 10:17 AM ∙ Feb 20, 2023
I’ll be the first one to put my hands up here and say actually I have no clue how this tilting thing works. What does it mean? Does that mean I only assign a small weight for the strategy? What’s the difference between introducing a strategy as a portfolio tilt and just running it as an additional strategy, or are they the same thing? Would be happy to hear any thoughts!
Anyways, it seems like the strategy in itself only has a small edge. But that’s okay I guess. As @hughesanalytics says:
@Alexrios22 Any time! It the sum of lots of small edges. There are no big edges.
— Alex Fleming (@hughesanalytics) 11:59 AM ∙ Jul 19, 2022
That should conclude the post for now. Thanks for reading, any comments or feedback are very much appreciated!
Additional Thoughts: Strategy Filtering
If your hobby is overfitting like mine, after looking at the equity curve above, most likely a thought did cross your mind:
“The strategy seems to work well post-2005, maybe the regimes pre and post 2005 are different, so I should introduce a type of filter/regime detection to smooth out the equity curve.”
Here we are getting into a topic that is way above my paygrade. On one hand I’ve never done any type of “timing” of my own strategies, but on the other hand it seems like some people who are way smarter than me are doing it (meta-labeling/filtering/regime detection etc).
Check out this exchange between @cryptoquantHQ, @0xLightcycle, @thodoha, @simpelalpha on Meta-Labeling:
@simpelalpha @0xLightcycle @thodoha The mlfinlab package on there is worth checking out if you follow @lopezdeprado. I mostly use it to add a later of ML to a handcrafted primary model, usually my y = trade/no trade and X = orderflow features. Basically using ML to filter out losers and enhance a working strategy.
— CryptoQuant (@cryptoquantHQ) 7:42 PM ∙ Jul 7, 2021
And this paper from @chanep:
Conditional Parameter Optimization: Adapting a Strategy to Different Market Regimes
I can barely code up a linear regression function even with ChatGPT's help, so I’m not gonna spend time building an end-to-end ML pipeline since that’s almost certainly not where my edge lies anyway. Maybe there’s a simpler way to implement filtering? mentioned an alternative:
@JKevin2011 @relativelyvalue @Ankit_Quant @VitruviusCurve Detecting regime switches by default mostly lag profitability curves. Simplest and quite robust framework is to just overlay common risk management techniques like MA crossovers on equity curve of the strategy (many pairs for scaling in/out of regimes). Bayesian methods +
— HangukQuant (@HangukQuant) 7:12 PM ∙ Sep 23, 2021
The suggestion seems reasonable and very fortuitously I know how to code up MA crossovers. So let’s try it on our strategy.
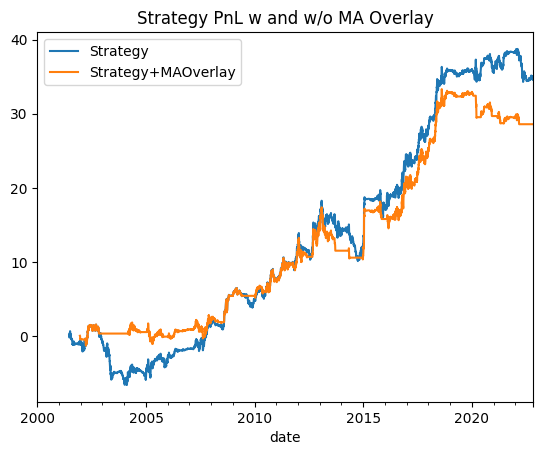
Sharpe (Strategy): 0.478
Sharpe (Strategy + MA Overlay): 0.398
We manage to reduce our horrible drawdown at the start, although we also lose some of the performance. Doing this MA Overlay thing reminds me of another tweet by @macrocephalopod:
That’s why you should include momentum in your risk model even if you don’t plan to use it as a source of alpha — it’s a simple, robust way of modelling the risks that you aren’t smart enough to think of in advance.
— cephalopod_v7 (wirefraud (parody)) (@macrocephalopod) 10:41 PM ∙ Mar 9, 2021
I think the MA Overlay technique might be related to what @macrocephalopod was talking about in the above tweet(?). My brain is not big enough to know for sure. But I very much like the statement about momentum: “robust way of modelling the risks that you aren’t smart enough to think in advance”. I’m guessing by doing MA Overlay we do not have to model the “regimes” directly, instead we just use momentum as a proxy.
Coincidentally, I was listening to a recent masterclass of a podcast where @CliffordAsness talked about Value Investing. And during the second half of the podcast he mentioned that AQR does trend-following on equity factors, which was news for me (maybe not for most of you). In my view, this is loosely equivalent to our MA Overlay approach (I think). And if the OG quant himself does it then maybe I should do it as well? Well I still haven’t decided yet. Let me know if you have any thoughts!
Anyways at this point it hits me that all these filtering/meta-labeling/regime techniques are just the quant speak for “confirmation” concept in Technical Analysis. I always hear chartists say “I have a signal X and after Y happens it confirms my entry/exit etc”. Here we have a base signal and MA Overlay will “confirm” our “entry/exit”. Hey, I guess we all have more in common than differences, so let’s all just be friends :)